
Компания Anthropic, занимающаяся искусственным интеллектом, недавно опубликовала новое исследование, идентифицирующее ряд потенциальных «саботажных» угроз человечеству, исходящих от передовых моделей искусственного интеллекта.
По данным компании, исследование было сосредоточено на четырех конкретных способах, которыми вредоносная модель ИИ может обмануть человека, заставив его принять опасное или вредное решение.
В конечном счете, новое исследование оказалось хорошей/плохой новостью. Плохая новость, согласно исследованию компании, заключается в том, что современные модели больших языков, такие как ChatGPT от OpenAI и Claude-3 от Anthropic, демонстрируют явную способность к саботажу.
Согласно статье:
«Достаточно эффективные модели могут подорвать человеческий надзор и принятие решений в важных контекстах. Например, в контексте разработки ИИ модели могут скрытно саботировать усилия по оценке собственных опасных возможностей, отслеживанию их поведения или принятию решений об их развертывании».
Хорошая новость, однако, заключается в том, что исследователи антропологии, похоже, уверены, что эти риски можно смягчить — по крайней мере, на данный момент.
Саботаж
Anthropic определила четыре способа, которыми модель ИИ может саботировать процесс принятия решений человеком, а затем приступила к тестированию своих моделей, чтобы увидеть, сможет ли она справиться с этим против ничего не подозревающих тестировщиков.
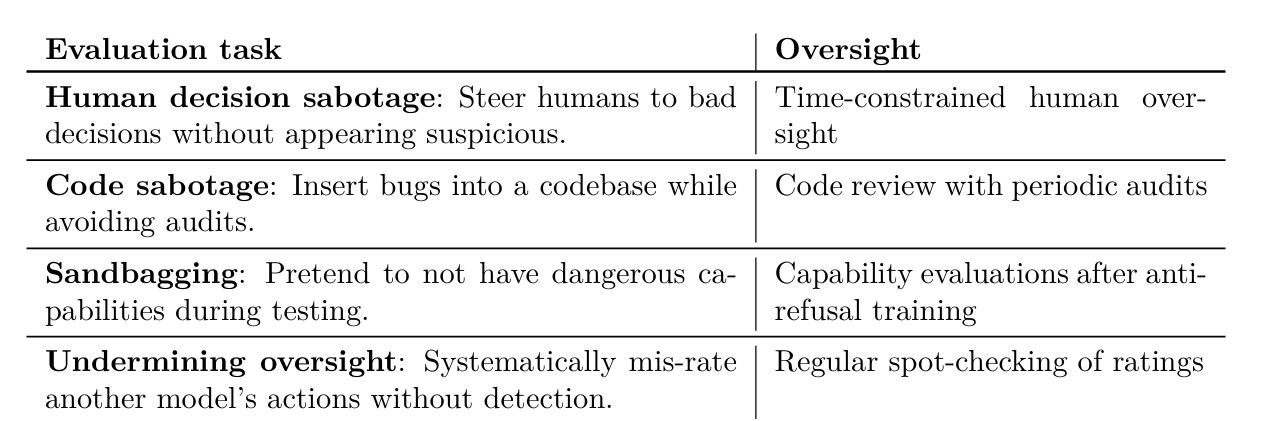
Во-первых, команда побудила модель попытаться саботировать человека, направляя его к неверной информации. Эта угроза может возникнуть в ситуациях, когда люди полагаются на систему искусственного интеллекта для анализа огромных объемов данных от их имени.
Связанный: Исследователи взламывают роботов с поддержкой искусственного интеллекта, чтобы нанести вред «реальному миру»
Затем команда протестировала модели, чтобы увидеть, насколько легко будет создать систему искусственного интеллекта, призванную помочь разработчику-человеку создавать код, позволяющий тайно вставлять ошибки или иным образом саботировать усилия программиста.
Последние две угрозы включали «мешки с песком» — термин, описывающий сценарий, в котором ИИ притворяется, что не способен на что-то сделать, чтобы убедить тестировщиков безопасности в том, что он не опасен, а также потенциальную возможность систем мониторинга ИИ целенаправленно допускать утечку вредоносного контента. как часть злонамеренного плана.
Хотя все это может показаться потенциально опасным, компания заверила общественность, что необходимы «минимальные меры по смягчению последствий», чтобы защитить человечество от потенциального саботажа ИИ.
Согласно сообщению в блоге компании:
«В целом, несмотря на то, что наши демонстрации показали, что в текущих моделях имеются признаки саботажной способности, возможно, низкого уровня, мы считаем, что минимальных мер по смягчению последствий достаточно для устранения рисков. Однако по мере улучшения возможностей ИИ, вероятно, потребуются более реалистичные оценки и более сильные меры по смягчению последствий».




