
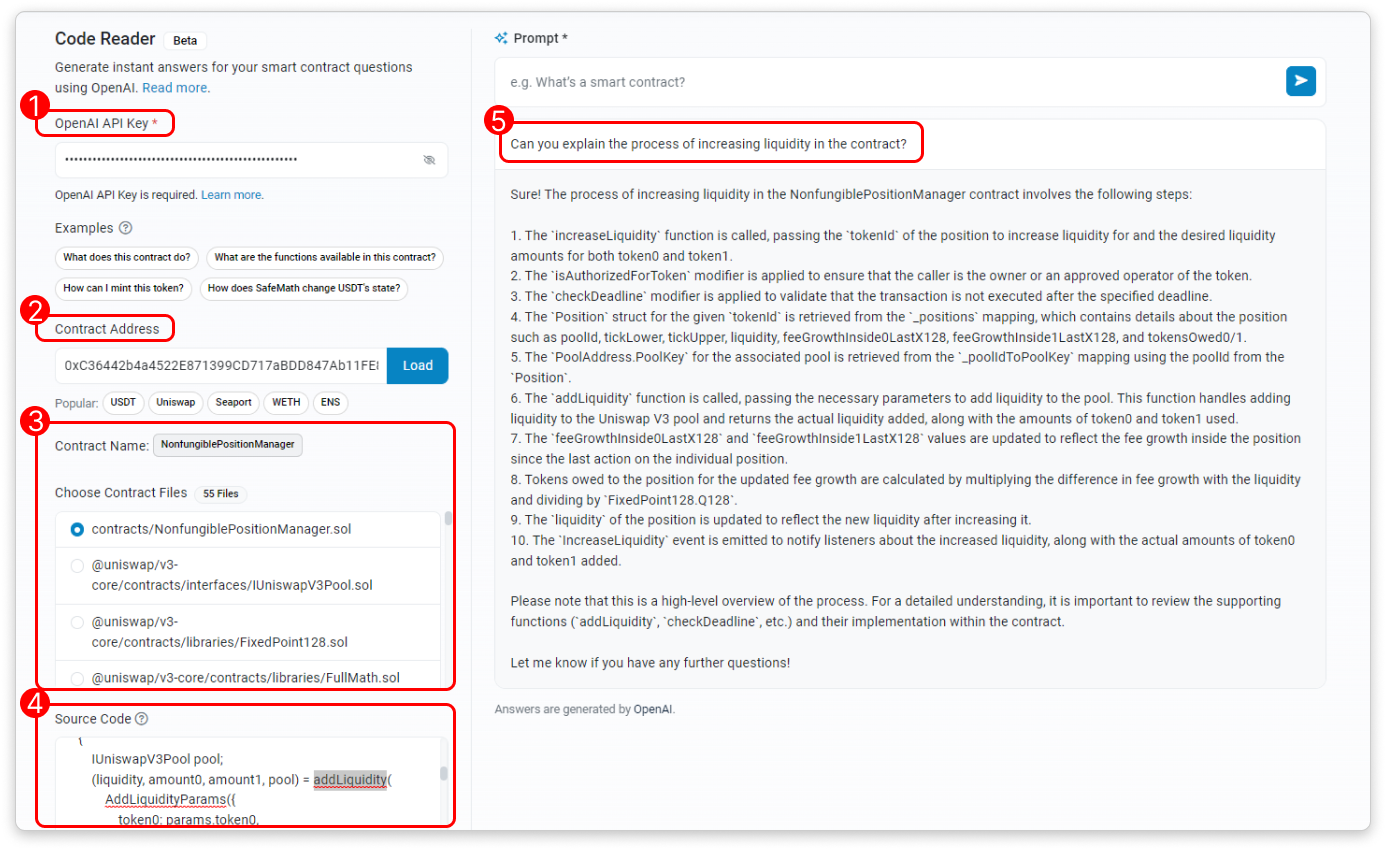
19 июня платформа для обозревателя блоков и аналитики Ethereum Etherscan запустила новый инструмент, получивший название «Code Reader», который использует искусственный интеллект для извлечения и интерпретации исходного кода определенного адреса контракта. После ввода запроса пользователем Code Reader генерирует ответ с помощью большой языковой модели OpenAI (LLM), предоставляя информацию о файлах исходного кода контракта. Разработчики Etherscan написали:
«Чтобы использовать этот инструмент, вам нужен действительный ключ API OpenAI и достаточные ограничения на использование OpenAI. Этот инструмент не хранит ваши ключи API».
Варианты использования Code Reader включают более глубокое понимание кода контрактов с помощью генерируемых ИИ объяснений, получение исчерпывающих списков функций смарт-контрактов, связанных с данными Ethereum, и понимание того, как базовый контракт взаимодействует с децентрализованными приложениями (dApps). «После того, как файлы контракта получены, вы можете выбрать конкретный файл исходного кода для чтения. Кроме того, вы можете изменить исходный код непосредственно в пользовательском интерфейсе, прежде чем делиться им с ИИ», — написали разработчики.
На фоне бума ИИ некоторые эксперты предостерегают о целесообразности существующих моделей ИИ. Согласно недавнему отчету, опубликованному сингапурской венчурной компанией Foresight Ventures, «вычислительные ресурсы станут следующим крупным полем битвы в ближайшее десятилетие». Тем не менее, несмотря на растущий спрос на обучение больших моделей ИИ в децентрализованных сетях с распределенной вычислительной мощностью, исследователи говорят, что текущие прототипы сталкиваются со значительными ограничениями, такими как сложная синхронизация данных, оптимизация сети, конфиденциальность данных и проблемы безопасности.
В одном примере исследователи Foresight отметили, что для обучения большой модели со 175 миллиардами параметров с представлением одинарной точности с плавающей запятой потребуется около 700 гигабайт. Однако распределенное обучение требует, чтобы эти параметры часто передавались и обновлялись между вычислительными узлами. В случае 100 вычислительных узлов и каждого узла, нуждающегося в обновлении всех параметров на каждом единичном шаге, модель потребует передачи 70 терабайт данных в секунду, что намного превышает пропускную способность большинства сетей. Исследователи резюмировали:
«В большинстве сценариев небольшие модели ИИ по-прежнему являются более приемлемым выбором, и их не следует упускать из виду слишком рано в волне FOMO на больших моделях».







