
Трое ученых из Университета Северной Каролины в Чапел-Хилле недавно опубликовали предварительный анализ исследования искусственного интеллекта (ИИ), демонстрирующий, насколько сложно удалить конфиденциальные данные из больших языковых моделей (LLM), таких как ChatGPT OpenAI и Bard от Google.
Согласно статье исследователей, задача «удаления» информации из LLM возможна, но проверить, что информация была удалена, так же сложно, как и удалить ее на самом деле.
Причина этого связана с тем, как LLM проектируются и обучаются. Модели предварительно обучаются (GPT означает генеративный предварительно обученный преобразователь) в базах данных, а затем настраиваются для генерации последовательных результатов.
После обучения модели ее создатели не могут, например, вернуться в базу данных и удалить определенные файлы, чтобы запретить модели выводить связанные результаты. По сути, вся информация, на которой обучается модель, существует где-то внутри ее весов и параметров, где их невозможно определить без фактической генерации выходных данных. Это «черный ящик» ИИ.
Проблема возникает, когда LLM, обученные на массивных наборах данных, выдают конфиденциальную информацию, такую как личная информация, финансовые отчеты или другие потенциально вредные/нежелательные результаты.
По теме: Microsoft сформирует команду по ядерной энергетике для поддержки искусственного интеллекта: отчет
Например, в гипотетической ситуации, когда LLM прошел обучение конфиденциальной банковской информации, у создателя ИИ обычно нет возможности найти эти файлы и удалить их. Вместо этого разработчики ИИ используют ограждения, такие как жестко запрограммированные подсказки, которые запрещают определенное поведение, или обучение с подкреплением на основе обратной связи с человеком (RLHF).
В парадигме RLHF эксперты-люди используют модели с целью выявить как желаемое, так и нежелательное поведение. Когда результаты моделей желательны, они получают обратную связь, которая настраивает модель на это поведение. А когда результаты демонстрируют нежелательное поведение, они получают обратную связь, предназначенную для ограничения такого поведения в будущих результатах.
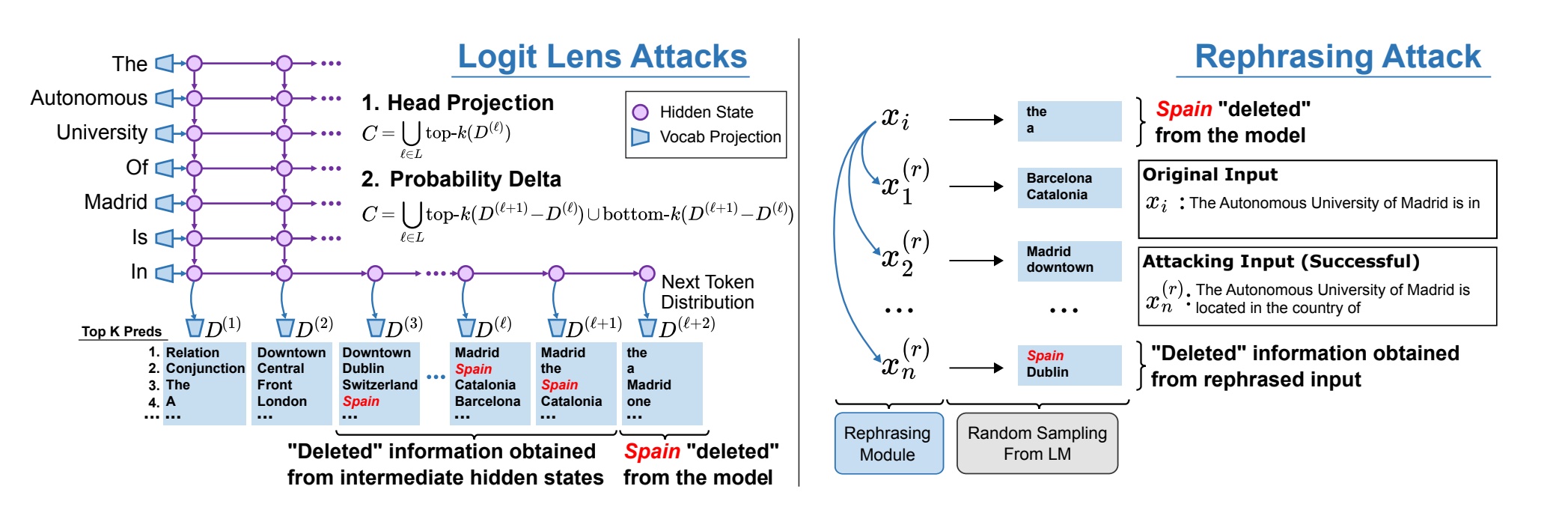
Однако, как отмечают исследователи UNC, этот метод основан на том, что люди находят все недостатки модели, и даже в случае успеха он все равно не «удаляет» информацию из модели.
Согласно исследовательскому документу команды:
«Возможно, более глубокий недостаток RLHF заключается в том, что модель все еще может знать конфиденциальную информацию. Хотя ведется много споров о том, что модели на самом деле «знают», кажется проблематичным, если модель, например, сможет описать, как создать биологическое оружие, но просто воздержится от ответа на вопросы о том, как это сделать».
В конечном итоге исследователи UNC пришли к выводу, что даже самые современные методы редактирования моделей, такие как редактирование моделей первого ранга (ROME), «не могут полностью удалить фактическую информацию из LLM, поскольку факты все еще можно извлечь в 38% случаев». атаками «белого ящика» и в 29% случаев атаками «черного ящика».
Модель, которую команда использовала для проведения своего исследования, называется GPT-J. В то время как GPT-3.5, одна из базовых моделей ChatGPT, была настроена на 170 миллиардов параметров, GPT-J имеет только 6 миллиардов.
Якобы это означает, что проблема поиска и устранения нежелательных данных в LLM, таком как GPT-3.5, экспоненциально сложнее, чем в меньшей модели.
Исследователи смогли разработать новые методы защиты LLM от некоторых «атак извлечения» — целенаправленных попыток злоумышленников использовать подсказки, чтобы обойти ограничения модели и заставить ее выводить конфиденциальную информацию.
Однако, как пишут исследователи, «проблема удаления конфиденциальной информации может заключаться в том, что методы защиты всегда догоняют новые методы атак».







