
Недавно компания Meta AI опубликовала предварительное исследование, демонстрирующее радикально новый фреймворк «Мегабайт» для создания систем генеративного предварительно обученного трансформатора (GPT).
Названная «многообещающей» Андреем Карпати из OpenAI, бывшим директором по искусственному интеллекту в Tesla, новая архитектура предназначена для обработки больших объемов данных, таких как изображения, романы и видеофайлы, без использования процесса, известного как токенизация.
Promising. Everyone should hope that we can throw away tokenization in LLMs. Doing so naively creates (byte-level) sequences that are too long, so the devil is in the details.
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with… https://t.co/t240ZPxPm7
— Andrej Karpathy (@karpathy) May 15, 2023
Токенизация — это процесс с потерями, сравнимый со сжатием файлов. Для обработки больших объемов данных модели GPT преобразуют байты в токены. Затем токены обрабатываются преобразователем и используются для генерации выходных токенов, которые затем декодируются.
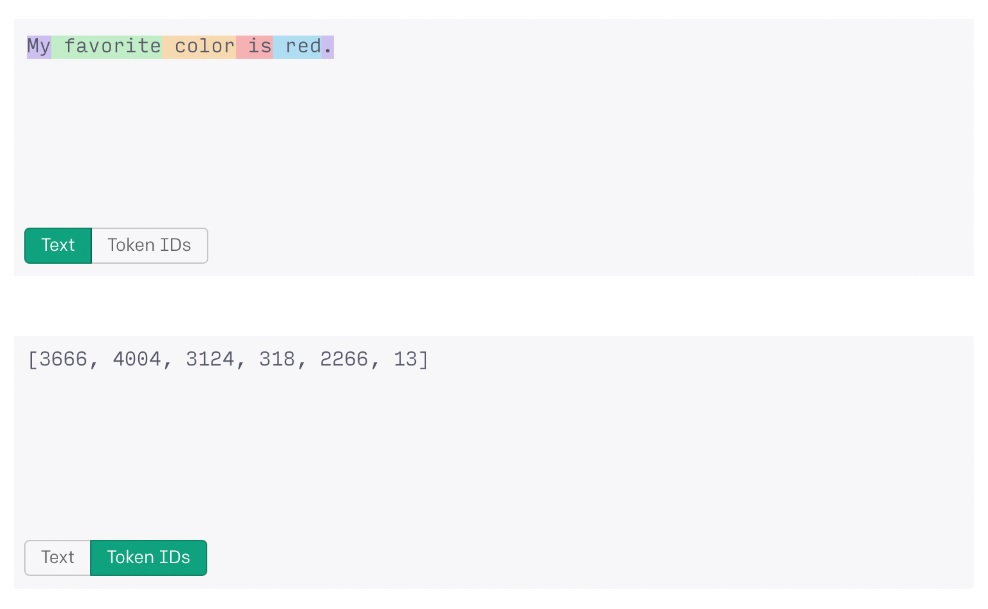
Процесс токенизации позволяет системе ИИ обрабатывать большие строки данных как числа. Например, слова «мой любимый цвет — красный» при обработке с помощью OpenAI ChatGPT будут преобразованы в строку токена «3666, 4004, 3124, 318, 2266, 13» для обработки.
К сожалению, даже с помощью токенизации объем данных, которые современные современные системы могут обрабатывать, по-прежнему имеет жесткий предел. Для GPT-3.5 ограничение составляет чуть более 4000 токенов или около 3000 слов, тогда как для GPT-4 максимальное значение составляет около 32000 токенов или около 24000 слов.
Новая система Megabyte от Meta отказывается от токенизации в пользу новой архитектуры многоуровневого прогнозирования, способной выполнять сквозное моделирование более 1 миллиона байтов данных.
Большинство стандартных англоязычных систем кодирования используют стандартную 8-битную кодировку. В этой парадигме каждый символ занимает один байт данных. Таким образом, система искусственного интеллекта, способная обрабатывать 1 миллион байт данных без токенизации, может работать с текстовыми документами, содержащими 750 000 слов, что на 3025% больше, чем в GPT-4.
Для сравнения, GPT-4 в настоящее время может обрабатывать около 10 полнометражных новостных статей за одно приглашение, в то время как Megabyte сможет анализировать всю книгу Льва Толстого «Война и мир» плюс еще два романа средней длины.
Модель Megabyte от Meta также показала хорошие результаты в тестах и тестах ImageNet, связанных с обработкой аудиофайлов, либо сравнявшись, либо превзойдя существующие модели преобразования на основе байтов, такие как Perciever AR от DeepMind, в обоих случаях:
«Megabyte соответствует самой современной производительности PerceiverAR, используя только половину вычислений».
Последствия этого исследования могут быть далеко идущими. Токенизация считается препятствием в этой области из-за ее жестких ограничений данных и количества энергии и времени, необходимых для обучения систем.
Без токенизации должно быть возможно обучать модели ИИ с более сильной фундаментальной поддержкой неанглийских языков, особенно тех, которые не могут быть легко закодированы стандартными 8-битными символами.
Это может привести к дальнейшей демократизации этих технологий и позволит встраивать все, от ботов для торговли криптовалютой до технологий децентрализованной автономной организации, в коды на родных языках по всему миру.
Связанный: Worldcoin Сэма Альтмана обеспечивает 115 миллионов долларов для децентрализованной идентификации
Это также увеличило бы возможности таких моделей, как ChatGPT, для работы с изображениями, видео и аудиофайлами за счет создания мультимедийных клипов, использующих примерно то же время и потребление энергии, что и текст.







