
Компания OpenAI, занимающаяся искусственным интеллектом, запустила «GPTBot» — свой новый инструмент для сканирования веб-страниц, который, по ее словам, потенциально может быть использован для улучшения будущих моделей ChatGPT.
«Веб-страницы, просканированные с помощью пользовательского агента GPTBot, потенциально могут быть использованы для улучшения будущих моделей», — говорится в новом сообщении в блоге OpenAI, добавив, что это может повысить точность и расширить возможности будущих итераций.
Поисковый робот, иногда называемый веб-пауком, представляет собой тип бота, который индексирует содержимое веб-сайтов в Интернете. Поисковые системы, такие как Google и Bing, используют их для того, чтобы веб-сайты отображались в результатах поиска.
OpenAI заявила, что веб-краулер будет собирать общедоступные данные из всемирной паутины, но будет отфильтровывать источники, для которых требуется платный контент, или которые, как известно, собирают личную информацию или содержат текст, нарушающий его политику.
Breaking
OpenAI just launched GPTBot, a web crawler designed to automatically scrape data from the entire internet.
This data will be used to train future AI models like GPT-4 and GPT-5!
GPTBot ensures that sources violating privacy and those behind paywalls are excluded. pic.twitter.com/oR3kY4buaU
— Shubham Saboo (@Saboo_Shubham_) August 7, 2023
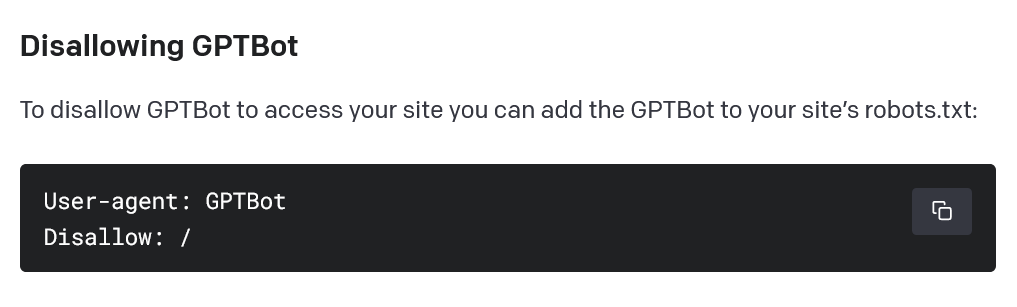
Следует отметить, что владельцы веб-сайтов могут запретить поисковый робот, добавив команду «запретить» в стандартный файл на сервере.
Новый гусеничный робот появился через три недели после того, как фирма подала заявку на регистрацию товарного знака «GPT-5», ожидаемого преемника текущей модели GPT-4.
Заявка была подана в Ведомство США по патентам и товарным знакам 18 июля и охватывает использование термина «GPT-5», который включает в себя программное обеспечение для человеческой речи и текста на основе искусственного интеллекта, преобразования аудио в текст и распознавания голоса и речи..
OpenAI has filed a trademark application for:
“GPT-5”
which includes “software for”:
“the artificial production of human speech and text”
“conversion of audio data files into text”
"voice and speech recognition"
"machine-learning based language and speech processing"
pic.twitter.com/54aJBovDNB
— YK aka CS Dojo (@ykdojo) August 1, 2023
Тем не менее, наблюдатели могут пока не захотеть затаить дыхание перед следующей итерацией ChatGPT. В июне основатель и генеральный директор OpenAI Сэм Альтман заявил, что фирма «далеко не близка» к началу обучения GPT-5, объяснив это тем, что до начала необходимо провести несколько проверок безопасности.
Связанный: 11 подсказок ChatGPT для максимальной производительности
Между тем, в последнее время были высказаны опасения по поводу тактики сбора данных OpenAI, особенно в отношении авторских прав и согласия.
Японский орган по надзору за конфиденциальностью предупредил OpenAI о сборе конфиденциальных данных без разрешения в июне, в то время как Италия временно запретила использование ChatGPT после того, как в апреле она заявила о нарушении различных законов о конфиденциальности Европейского Союза.
В конце июня 16 истцов подали коллективный иск против OpenAI, утверждая, что фирма, занимающаяся искусственным интеллектом, получила доступ к частной информации из взаимодействий пользователей ChatGPT.
Если эти обвинения подтвердятся, OpenAI — и Microsoft, которая была названа ответчиком, — нарушат Закон о компьютерном мошенничестве и злоупотреблениях, закон с прецедентом для случаев веб-скрейпинга.






