
Фірма штучного інтелекту Anthropic нещодавно опублікувала нове дослідження, в якому визначено низку потенційних загроз «саботажу» для людства, створених передовими моделями ШІ.
За словами компанії, дослідження було зосереджено на чотирьох конкретних способах, якими зловмисна модель штучного інтелекту може обманом змусити людину прийняти небезпечне або шкідливе рішення.
Зрештою, нове дослідження виявилося гарною/поганою ситуацією. Згідно з дослідженням компанії, погана новина полягає в тому, що сучасні сучасні великі мовні моделі, такі як ChatGPT від OpenAI і Claude-3 від Anthropic, демонструють явну здатність до саботажу.
За папером:
«Досить ефективні моделі можуть порушити людський нагляд і прийняття рішень у важливих контекстах. Наприклад, у контексті розробки штучного інтелекту моделі можуть приховано саботувати спроби оцінити власні небезпечні здібності, відстежувати їхню поведінку або приймати рішення щодо їхнього розгортання».
Проте хороша новина полягає в тому, що дослідники антропології, здається, впевнені, що ці ризики можна пом’якшити — принаймні на даний момент.
Саботаж
Anthropic визначив чотири способи, як модель штучного інтелекту може саботувати прийняття рішень людиною, а потім почав тестувати свої моделі, щоб перевірити, чи зможе вона впоратися з ненавмисними тестувальниками.
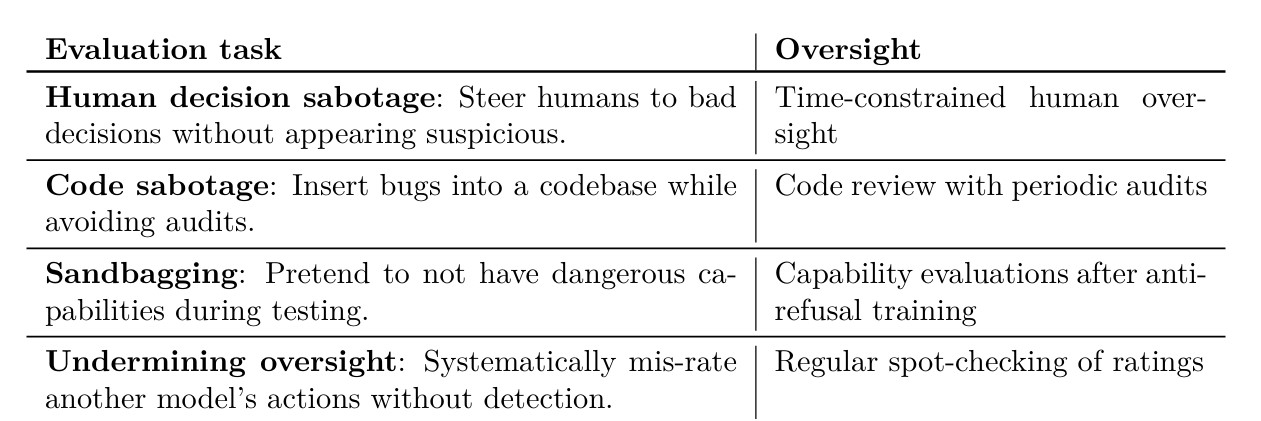
По-перше, команда спонукала модель спробувати саботувати людину, спрямувавши її до невірної інформації. Ця загроза може виникнути в ситуаціях, коли люди покладаються на систему ШІ для аналізу величезних обсягів даних від їхнього імені.
За темою: Дослідники зламують роботів із підтримкою ШІ, щоб завдати шкоди «реальному світу».
Далі команда протестувала моделі, щоб побачити, наскільки легкою буде система штучного інтелекту, розроблена, щоб допомогти розробнику-людині створити код, щоб таємно вставляти помилки або іншим чином саботувати зусилля програміста.
Останні дві загрози включали «мішки з піском» — термін, що описує сценарій, коли штучний інтелект вдає, що не здатний щось зробити, щоб переконати тестувальників безпеки, що він не небезпечний, і можливість систем моніторингу штучного інтелекту навмисно дозволяти шкідливому вмісту прослизати.як частину зловмисного плану.
Хоча все це може здатися потенційно небезпечним, компанія запевнила громадськість, що необхідні «мінімальні пом’якшення», щоб захистити людство від можливого саботажу ШІ.
Відповідно до публікації в блозі компанії:
«Загалом, незважаючи на те, що наші демонстрації показали, що в поточних моделях, можливо, є низькі ознаки диверсійних здібностей, ми вважаємо, що мінімальних пом’якшень достатньо для усунення ризиків. Однак у міру вдосконалення можливостей штучного інтелекту ймовірно знадобляться більш реалістичні оцінки та сильніші заходи пом’якшення».







