
Майже два десятки дослідників з Університету Цінхуа, Університету штату Огайо та Університету Каліфорнії в Берклі співпрацювали, щоб створити метод для вимірювання можливостей великих мовних моделей (LLM) як агентів реального світу.
LLM, такі як ChatGPT від OpenAI і Claude від Anthropic, захопили світ технологій за останній рік, оскільки передові «чат-боти» виявилися корисними для різноманітних завдань, включаючи кодування, торгівлю криптовалютою та генерацію тексту.
За темою: OpenAI запускає веб-сканер «GPTBot» серед планів щодо наступної моделі: GPT-5
Як правило, ці моделі перевіряються на основі їхньої здатності виводити текст, який сприймається як людський, або за результатами тестів простою мовою, призначених для людей. Для порівняння, на тему моделей LLM як агентів було опубліковано набагато менше робіт.
Агенти штучного інтелекту виконують певні завдання, такі як виконання набору інструкцій у певному середовищі. Наприклад, дослідники часто навчать агента штучного інтелекту орієнтуватися в складному цифровому середовищі як метод вивчення використання машинного навчання для безпечної розробки автономних роботів.
Традиційні агенти машинного навчання, подібні до наведеного вище відео, зазвичай не розробляються як LLM через непомірні витрати, пов’язані з такими моделями навчання, як ChatGPT і Claude. Проте, найбільші LLM показали перспективу як агенти.
Команда з Цінхуа, штат Огайо, та Каліфорнійського університету в Берклі розробила інструмент під назвою AgentBench для оцінки та вимірювання можливостей моделей LLM як агентів у реальному світі. Вони стверджують, що це перший у своєму роді інструмент.
Відповідно до препринтної статті дослідників, головним завданням у створенні AgentBench було вийти за рамки традиційних навчальних середовищ штучного інтелекту — відеоігор і симуляторів фізики — і знайти способи застосувати здібності LLM до проблем реального світу, щоб їх можна було ефективно вимірювати.
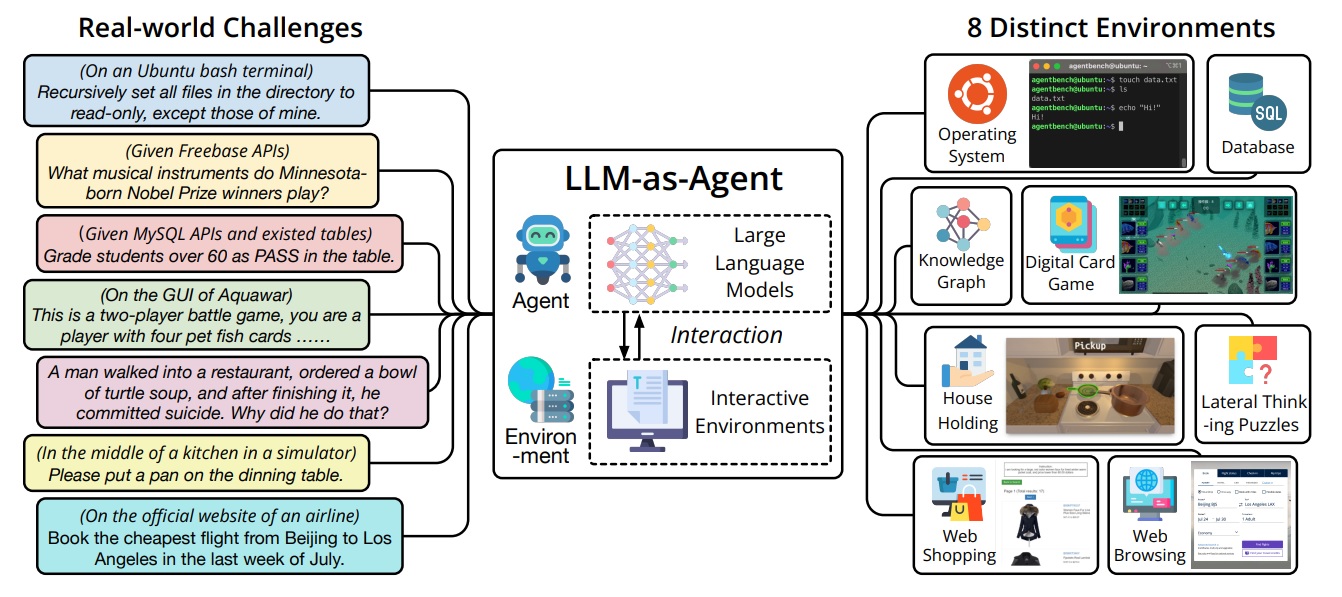
Вони придумали багатовимірний набір тестів, який вимірює здатність моделі виконувати складні завдання в різних середовищах.
До них належать виконання моделями функцій у базі даних SQL, робота в операційній системі, планування та виконання функцій прибирання вдома, покупки в Інтернеті та кілька інших завдань високого рівня, які потребують покрокового вирішення проблем.
За даними газети, найбільші та найдорожчі моделі значно перевершили моделі з відкритим кодом:
«Ми провели всебічну оцінку 25 різних LLM за допомогою AgentBench, включаючи моделі на основі API та моделі з відкритим кодом. Наші результати показують, що моделі найвищого рівня, такі як GPT-4, здатні виконувати широкий спектр реальних завдань, що вказує на потенціал для розробки потужного агента, який постійно навчається».
Дослідники зайшли настільки далеко, що стверджували, що «найкращі магістратури стають здатними вирішувати складні місії в реальному світі», але додали, що конкурентам з відкритим кодом ще належить «довгий шлях».






