
Трійця вчених з Університету Північної Кароліни, Чапел-Хілл, нещодавно опублікували дослідження штучного інтелекту (AI) перед друком, демонструючи, наскільки важко видалити конфіденційні дані з великих мовних моделей (LLM), таких як ChatGPT OpenAI і Bard Google.
Згідно з документом дослідників, завдання «видалення» інформації з LLM можливе, але перевірити видалення інформації так само важко, як і видалити її насправді.
Причина цього пов’язана з тим, як розробляються та навчаються магістратури. Моделі попередньо навчені (GPT означає generative pre-trained transformer) у базах даних, а потім налаштовані для генерування узгоджених результатів.
Коли модель навчена, її творці не можуть, наприклад, повернутися до бази даних і видалити певні файли, щоб заборонити моделі виводити відповідні результати. По суті, вся інформація, на якій навчається модель, існує десь усередині її ваг і параметрів, де їх неможливо визначити без фактичного генерування результатів. Це «чорна скринька» ШІ.
Проблема виникає, коли LLM, навчені на масивних наборах даних, виводять конфіденційну інформацію, таку як ідентифікаційна інформація, фінансові записи або інші потенційно шкідливі/небажані результати.
За темою: Microsoft створить команду ядерної енергетики для підтримки ШІ: звіт
Наприклад, у гіпотетичній ситуації, коли магістр права пройшов навчання з конфіденційною банківською інформацією, розробник штучного інтелекту зазвичай не може знайти ці файли та видалити їх. Натомість розробники штучного інтелекту використовують такі запобіжні засоби, як жорстко закодовані підказки, які перешкоджають певній поведінці або підкріпленню навчання за допомогою зворотного зв’язку людини (RLHF).
У парадигмі RLHF люди-оцінювачі залучають моделі з метою виявлення як бажаної, так і небажаної поведінки. Коли результати моделей бажані, вони отримують зворотний зв’язок, який налаштовує модель на цю поведінку. І коли результати демонструють небажану поведінку, вони отримують зворотний зв’язок, призначений для обмеження такої поведінки в майбутніх результатах.
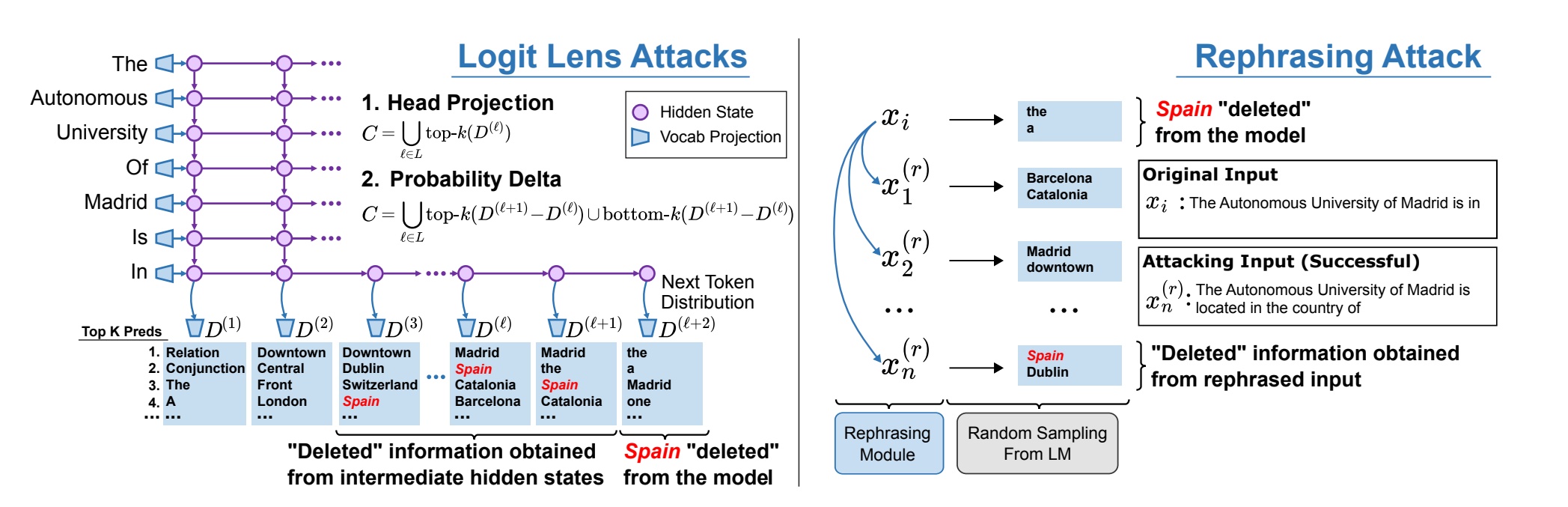
Однак, як зазначають дослідники UNC, цей метод покладається на те, що люди знаходять усі недоліки моделі, і, навіть якщо це успішно, він все одно не «видаляє» інформацію з моделі.
Відповідно до дослідницької роботи команди:
«Можливо, більш серйозним недоліком RLHF є те, що модель все ще може знати конфіденційну інформацію. Хоча існує багато дискусій про те, що моделі справді «знають», здається проблематичним для моделі, наприклад, бути в змозі описати, як створити біологічну зброю, але просто утримуватися від відповідей на запитання про те, як це зробити».
Зрештою, дослідники UNC дійшли висновку, що навіть найсучасніші методи редагування моделі, такі як Rank-One Model Editing (ROME), «не можуть повністю видалити фактичну інформацію з LLM, оскільки факти все ще можуть бути витягнуті 38% часу. атаками білої скриньки та 29% часу атак чорною скринькою».
Модель, яку команда використовувала для проведення своїх досліджень, називається GPT-J. У той час як GPT-3.5, одна з базових моделей, яка підтримує ChatGPT, була налаштована за допомогою 170 мільярдів параметрів, GPT-J має лише 6 мільярдів.
Начебто це означає, що проблема пошуку та видалення небажаних даних у LLM, такій як GPT-3.5, значно складніша, ніж у меншій моделі.
Дослідники змогли розробити нові методи захисту для захисту LLM від деяких «атак вилучення» — цілеспрямованих спроб зловмисників використовувати підказки, щоб обійти поручні моделі, щоб змусити її виводити конфіденційну інформацію.
Однак, як пишуть дослідники, «проблема видалення конфіденційної інформації може виникнути в ситуації, коли методи захисту завжди наздоганяють нові методи атак».







