
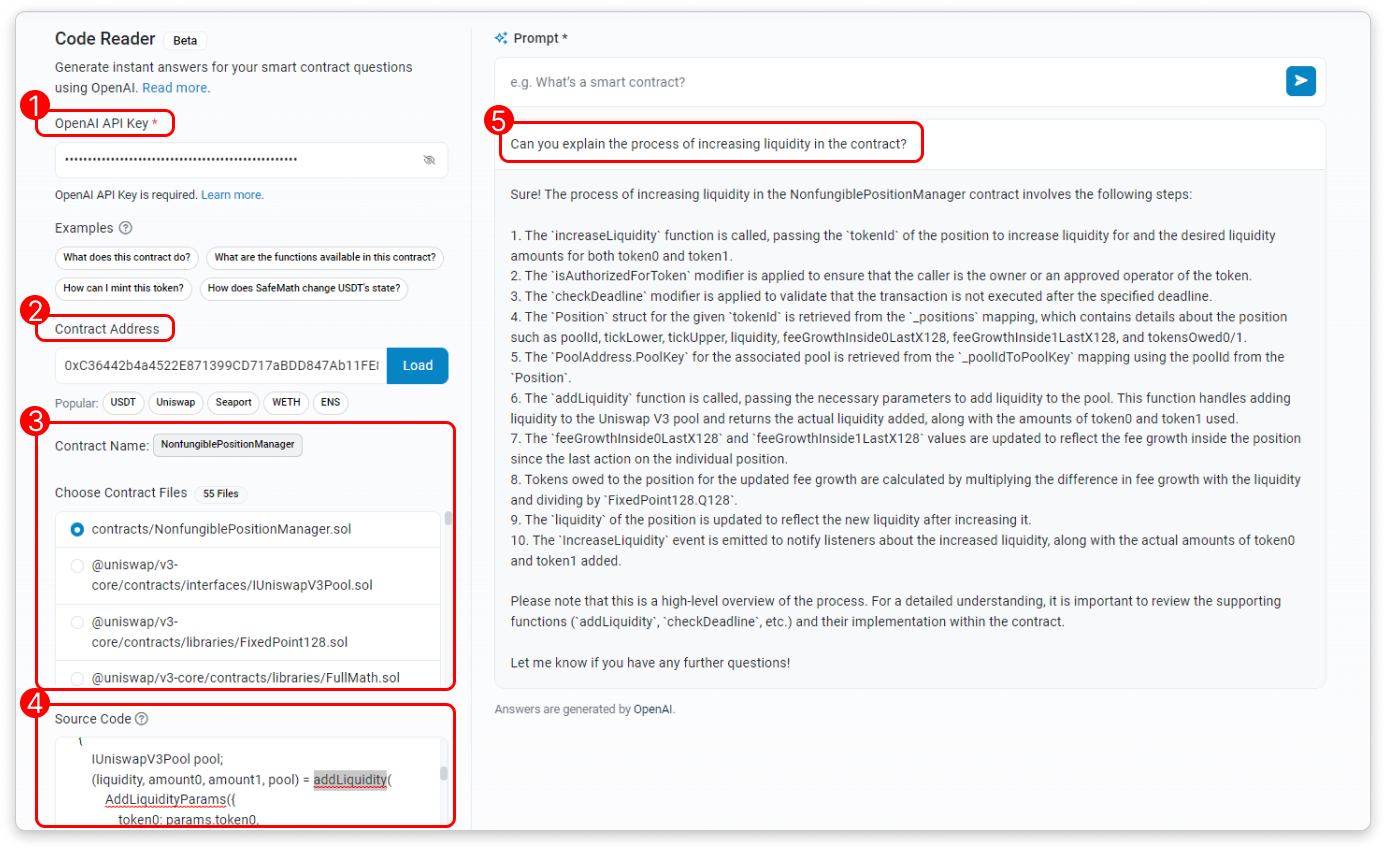
19 червня дослідник блоків і аналітична платформа Ethereum Etherscan запустила новий інструмент, який отримав назву «Code Reader», який використовує штучний інтелект для отримання та інтерпретації вихідного коду конкретної адреси контракту. Після введення запиту користувачем Code Reader генерує відповідь за допомогою великої мовної моделі OpenAI (LLM), надаючи розуміння файлів вихідного коду контракту. Розробники Etherscan написали:
«Щоб використовувати інструмент, вам потрібен дійсний ключ OpenAI API і достатні обмеження на використання OpenAI. Цей інструмент не зберігає ваші ключі API».
Варіанти використання Code Reader включають глибше розуміння коду контрактів за допомогою пояснень, створених ШІ, отримання вичерпних списків функцій смарт-контрактів, пов’язаних з даними Ethereum, і розуміння того, як основний контракт взаємодіє з децентралізованими програмами (dApps). «Після отримання файлів контракту ви можете вибрати певний файл вихідного коду для читання. Крім того, ви можете змінити вихідний код безпосередньо в інтерфейсі користувача, перш ніж поділитися ним з ШІ», — пишуть розробники.
На тлі буму штучного інтелекту деякі експерти застерігають щодо доцільності сучасних моделей штучного інтелекту. Відповідно до нещодавнього звіту, опублікованого сінгапурською фірмою венчурного капіталу Foresight Ventures, «комп’ютерні ресурси стануть наступним великим полем битви в найближче десятиліття». Тим не менш, незважаючи на зростаючий попит на навчання великих моделей штучного інтелекту в децентралізованих розподілених обчислювальних потужних мережах, дослідники кажуть, що поточні прототипи стикаються зі значними обмеженнями, такими як складна синхронізація даних, оптимізація мережі, конфіденційність даних і проблеми безпеки.
В одному прикладі дослідники Foresight зазначили, що для навчання великої моделі з 175 мільярдами параметрів із представленням із плаваючою комою одинарної точності знадобиться близько 700 гігабайт. Однак розподілене навчання вимагає частої передачі та оновлення цих параметрів між обчислювальними вузлами. У випадку 100 обчислювальних вузлів і кожному вузлу потрібно оновлювати всі параметри на кожному одиничному кроці, модель вимагатиме передачі 70 терабайт даних за секунду, що значно перевищує пропускну здатність більшості мереж. Дослідники резюмували:
«У більшості сценаріїв малі моделі штучного інтелекту все ще є більш прийнятним вибором, і їх не слід ігнорувати занадто рано в хвилі FOMO для великих моделей».






