
Meta AI нещодавно опублікував дослідження перед друком, демонструючи радикальну нову «мегабайтну» структуру для створення генеративних попередньо навчених трансформаторних систем (GPT).
Андрій Карпаті з OpenAI, колишній директор відділу штучного інтелекту в Tesla, назвав «багатообіцяючою» нову архітектуру, призначену для обробки великих обсягів даних — таких як зображення, романи та відеофайли — без використання процесу, відомого як токенізація.
Promising. Everyone should hope that we can throw away tokenization in LLMs. Doing so naively creates (byte-level) sequences that are too long, so the devil is in the details.
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with… https://t.co/t240ZPxPm7
— Andrej Karpathy (@karpathy) May 15, 2023
Токенізація — процес із втратами даних, який можна порівняти зі стисненням файлів. Для обробки великих обсягів даних моделі GPT перетворюють байти на маркери. Потім маркери обробляються трансформатором і використовуються для створення вихідних маркерів, які потім декодуються.
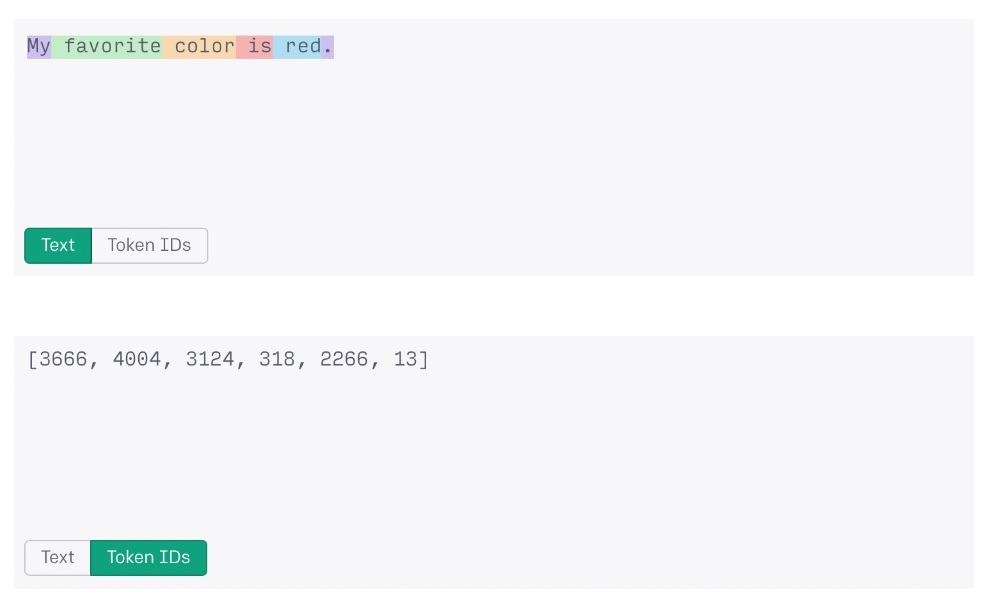
Процес токенізації дозволяє системі ШІ обробляти великі рядки даних як числа. Наприклад, слова «мій улюблений колір — червоний», якщо вони оброблені OpenAI’s ChatGPT, будуть перетворені на рядок маркерів «3666, 4004, 3124, 318, 2266, 13» для обробки.
На жаль, навіть завдяки токенізації кількість даних, які можуть обробити сучасні сучасні системи, все ще має жорстке обмеження. Для GPT-3.5 обмеження становить трохи більше 4000 токенів або близько 3000 слів, тоді як GPT-4 досягає максимуму приблизно в 32 000 токенів або близько 24 000 слів.
Нова система Megabyte від Meta відмовляється від токенізації на користь нової багаторівневої архітектури прогнозування, здатної наскрізного моделювання понад 1 мільйона байтів даних.
Більшість стандартних англомовних систем кодування використовують стандартне 8-бітне кодування. У цій парадигмі кожен символ займає один байт даних. Таким чином, система штучного інтелекту, здатна обробляти 1 мільйон байт даних без токенізації, може працювати з текстовими документами, що містять 750 000 слів — це на 3025% більше, ніж GPT-4.
Для порівняння, GPT-4 наразі може обробляти близько 10 повнометражних новинних статей в одному запиті, тоді як Megabyte зможе проаналізувати весь «Війну і мир» Льва Толстого плюс ще два романи середньої довжини.
Модель Meta Megabyte також показала хороші результати в тестах ImageNet і контрольних тестах, пов’язаних з обробкою аудіофайлів, дорівнюючи або перевершуючи існуючі байтові трансформаторні моделі, такі як Perciever AR від DeepMind, в обох випадках:
«Мегабайт відповідає сучасній продуктивності PerceiverAR, використовуючи лише половину обчислювальної інформації».
Наслідки цього дослідження можуть бути далекосяжними. Токенізація вважається перешкодою в цій галузі через жорсткі обмеження даних та кількість енергії та часу, необхідних для навчання систем.
Без токенізації можна буде навчити моделі ШІ з більшою базовою підтримкою неанглійських мов, особливо тих, які не можна легко закодувати стандартними 8-бітними символами.
Це може призвести до подальшої демократизації цих технологій і дозволить створювати все, від ботів для торгівлі криптовалютою до технологій децентралізованої автономної організації, у кодах рідної мови по всьому світу.
За темою: Worldcoin Сема Альтмана забезпечує 115 мільйонів доларів США за децентралізований ідентифікатор
Це також збільшить здатність таких моделей, як ChatGPT, працювати з файлами зображень, відео та аудіофайлами шляхом генерації мультимедійних кліпів, використовуючи приблизно той самий час і енергоспоживання, що й текст.






