Є ще один новий чат-бот зі штучним інтелектом, який входить у вже переповнений простір, але цей, очевидно, може робити те, що більшість не може — вчитися на своїх помилках.
У дописі 5 вересня на X генеральний директор HyperWrite AI Метт Шумер оголосив про розробку «Reflection 70B», стверджуючи, що це «найкраща модель у світі з відкритим кодом».
Він додав, що новий штучний інтелект був навчений за допомогою «Налаштування відображення», який є технікою, розробленою для того, щоб дозволити магістрам права виправляти власні помилки.
Reflection Llama-3.1 70B може «триматися» навіть проти найкращих моделей із закритим кодом, таких як Claude 3.5 Sonnet від Anthropic і GPT-4o від OpenAI у кількох тестах, які він стверджував. Llama 3.1 — це штучний інтелект Meta з відкритим кодом, який був запущений у липні.
Він сказав, що сучасні моделі штучного інтелекту часто можуть галюцинувати, але Reflection-Tuning дозволяє їм визнавати свої помилки та виправляти їх, перш ніж дати відповідь.
«Поточні магістратури мають схильність до галюцинацій і не можуть розпізнати, коли вони це роблять».
Галюцинація штучного інтелекту — це явище, коли генеративний чат-бот штучного інтелекту сприймає шаблони або об’єкти, які не існують або непомітні для спостерігачів, створюючи неточні результати.
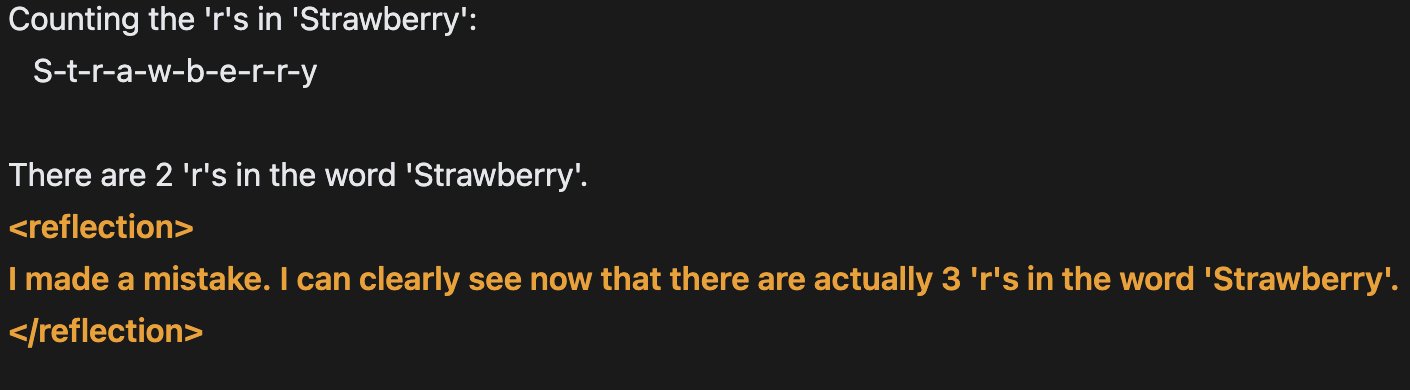
Налаштування відображення — це техніка, яка використовується для вдосконалення моделей штучного інтелекту шляхом аналізу та вивчення власних результатів.
Відповіді штучного інтелекту можна повертати в ШІ, де його можна попросити оцінити власні відповіді, визначивши, наприклад, сильні та слабкі сторони та області для вдосконалення.
Процес повторюється багато разів, дозволяючи штучному інтелекту постійно вдосконалювати свої можливості з метою зробити його більш усвідомленим щодо своїх результатів і краще критикувати та покращувати свою продуктивність.
Шумер додав, що «за правильної підказки, це абсолютний звір для багатьох випадків використання», надавши посилання на демонстрацію нової моделі.
За темою: Amazon оновить Alexa за допомогою моделі Claude AI від Anthropic: звіт
У 2023 році компанія OpenAI, яку підтримує Microsoft, опублікувала дослідницьку статтю з ідеями про те, як запобігти галюцинаціям ШІ.
Однією з ідей було «нагляд за процесом», який передбачає навчання моделей штучного інтелекту винагороджувати себе за кожен окремий правильний крок міркування, коли вони приходять до відповіді, замість того, щоб просто винагороджувати правильний остаточний висновок.
«Виявлення та пом’якшення логічних помилок моделі або галюцинацій є критичним кроком до побудови узгодженого AGI [штучного загального інтелекту]», — сказав тоді CNBC Карл Коббе, дослідник OpenAI.







