
OpenAI, розробник ChatGPT, виступає за використання штучного інтелекту (ШІ) у модерації вмісту, стверджуючи, що він може підвищити ефективність роботи платформ соціальних мереж шляхом прискорення обробки складних завдань.
Компанія штучного інтелекту, яку підтримує Microsoft, заявила, що її остання модель штучного інтелекту GPT-4 має можливість значно скоротити терміни модерації вмісту з місяців до декількох годин, забезпечуючи покращену узгодженість у маркуванні.
Модерація вмісту становить складну роботу для компаній соціальних мереж, таких як Meta, материнська компанія Facebook, що вимагає координації численних модераторів у всьому світі, щоб запобігти доступу користувачів до шкідливих матеріалів, таких як дитяча порнографія та зображення надзвичайно насильницького характеру.
«Процес (модерації вмісту) за своєю суттю повільний і може призвести до психічного стресу для людей-модераторів. Завдяки цій системі процес розробки та налаштування політики вмісту скорочується з місяців до годин».
Відповідно до заяви, OpenAI активно досліджує використання великих мовних моделей (LLM) для вирішення цих проблем. Його широкі мовні моделі, такі як GPT-4, мають здатність розуміти та створювати природну мову, що робить їх придатними для модерування вмісту. Ці моделі мають здатність приймати модераційні рішення, керуючись наданими їм політичними вказівками.
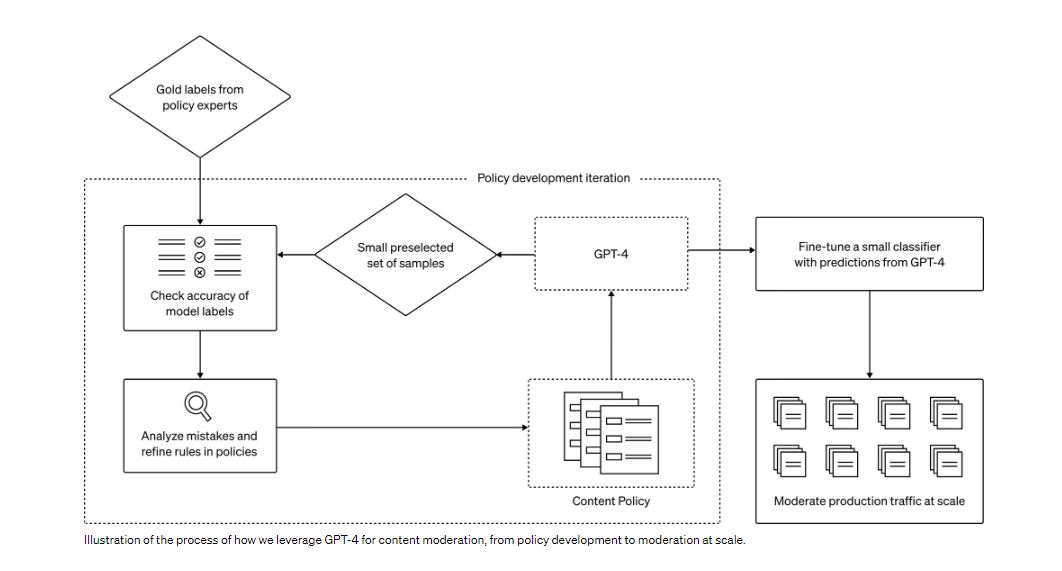
Прогнози GPT-4 можуть удосконалити менші моделі для обробки великих даних. Ця концепція покращує модерацію вмісту декількома способами, включаючи узгодженість міток, швидкий цикл зворотного зв’язку та полегшення психічного тягаря.
У заяві підкреслюється, що OpenAI наразі працює над підвищенням точності прогнозів GPT-4. Одним із шляхів, які досліджуються, є інтеграція ланцюжка думок або самокритики. Крім того, компанія експериментує з методами виявлення незнайомих ризиків, черпаючи натхнення з Конституційного штучного інтелекту.
За темою: у Китаї набувають чинності нові правила штучного інтелекту
Метою OpenAI є використання моделей для виявлення потенційно шкідливого вмісту на основі широких описів шкоди. Стаття, отримана в результаті цих зусиль, сприятиме вдосконаленню поточної політики щодо контенту або розробці нових у невивчених сферах ризику.
Крім того, 15 серпня генеральний директор OpenAI Сем Альтман уточнив, що компанія утримується від навчання своїх моделей штучного інтелекту за допомогою даних, створених користувачами.






