
Фірма зі штучного інтелекту OpenAI запустила «GPTBot» — свій новий інструмент веб-сканування, який, за її словами, потенційно може бути використаний для вдосконалення майбутніх моделей ChatGPT.
«Веб-сторінки, скановані за допомогою агента користувача GPTBot, потенційно можуть бути використані для вдосконалення майбутніх моделей», — йдеться в новому дописі в блозі OpenAI, додаючи, що це може підвищити точність і розширити можливості майбутніх ітерацій.
Веб-сканер, який іноді називають веб-павуком, — це тип бота, який індексує вміст веб-сайтів в Інтернеті. Такі пошукові системи, як Google і Bing, використовують їх, щоб веб-сайти відображалися в результатах пошуку.
OpenAI заявив, що веб-сканер збиратиме загальнодоступні дані з всесвітньої павутини, але відфільтровуватиме джерела, які вимагають платного вмісту, або, як відомо, збирають особисту інформацію, або містять текст, який порушує його політику.
Breaking
OpenAI just launched GPTBot, a web crawler designed to automatically scrape data from the entire internet.
This data will be used to train future AI models like GPT-4 and GPT-5!
GPTBot ensures that sources violating privacy and those behind paywalls are excluded. pic.twitter.com/oR3kY4buaU
— Shubham Saboo (@Saboo_Shubham_) August 7, 2023
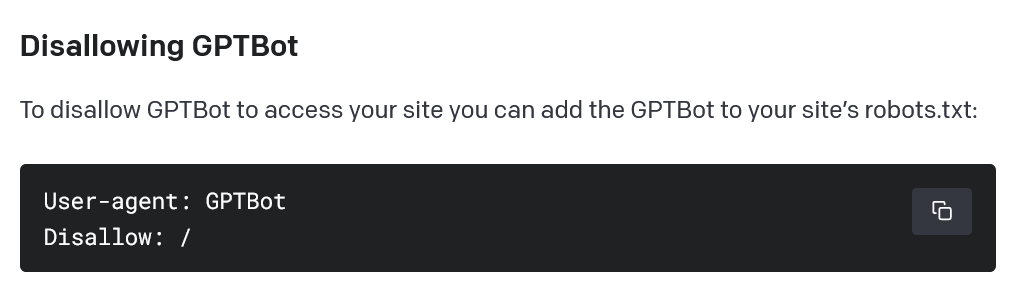
Слід зазначити, що власники веб-сайтів можуть заборонити роботу веб-сканера, додавши команду «disallow» до стандартного файлу на сервері.
Новий сканер з’явився через три тижні після того, як фірма подала заявку на торговельну марку «GPT-5», очікуваного наступника поточної моделі GPT-4.
Заявку було подано до Бюро патентів і торгових марок США 18 липня, і вона стосується використання терміну «GPT-5», який включає програмне забезпечення для людської мови та тексту на основі штучного інтелекту, перетворення звуку в текст і розпізнавання голосу та мови..
OpenAI has filed a trademark application for:
“GPT-5”
which includes “software for”:
“the artificial production of human speech and text”
“conversion of audio data files into text”
"voice and speech recognition"
"machine-learning based language and speech processing"
pic.twitter.com/54aJBovDNB
— YK aka CS Dojo (@ykdojo) August 1, 2023
Однак спостерігачі, можливо, не захочуть затамувати подих перед наступною ітерацією ChatGPT. У червні засновник і генеральний директор OpenAI Сем Альтман заявив, що фірма «не наближається» до початку навчання GPT-5, пояснивши, що перед початком необхідно провести кілька перевірок безпеки.
За темою: 11 підказок ChatGPT для максимальної продуктивності
Тим часом останнім часом висловлюються занепокоєння щодо тактики збору даних OpenAI, особливо щодо авторського права та згоди.
У червні японська служба захисту конфіденційності попередила OpenAI про збір конфіденційних даних без дозволу, а Італія тимчасово заборонила використання ChatGPT після того, як у квітні він порушив різні закони Європейського Союзу про конфіденційність.
Наприкінці червня проти OpenAI було подано колективний позов 16 позивачами, які стверджували, що фірма штучного інтелекту мала доступ до приватної інформації під час взаємодії користувачів ChatGPT.
Якщо буде доведено, що ці звинувачення є точними, OpenAI — і Microsoft, яку було названо відповідачем — порушуватимуть Закон про комп’ютерне шахрайство та зловживання, закон із прецедентом для випадків веб-збирання.






