
Кілька моделей штучного інтелекту ігнорують та активно саботували сценарії відключення під час контрольованих тестів, навіть коли явно доручили дозволити дію, стверджує дослідження Palisade.
Три моделі AI ігнорували інструкцію та успішно саботували сценарій відключення хоча б один раз під час 100 пробіжок, заявила дослідницька фірма в пост 24 травня.
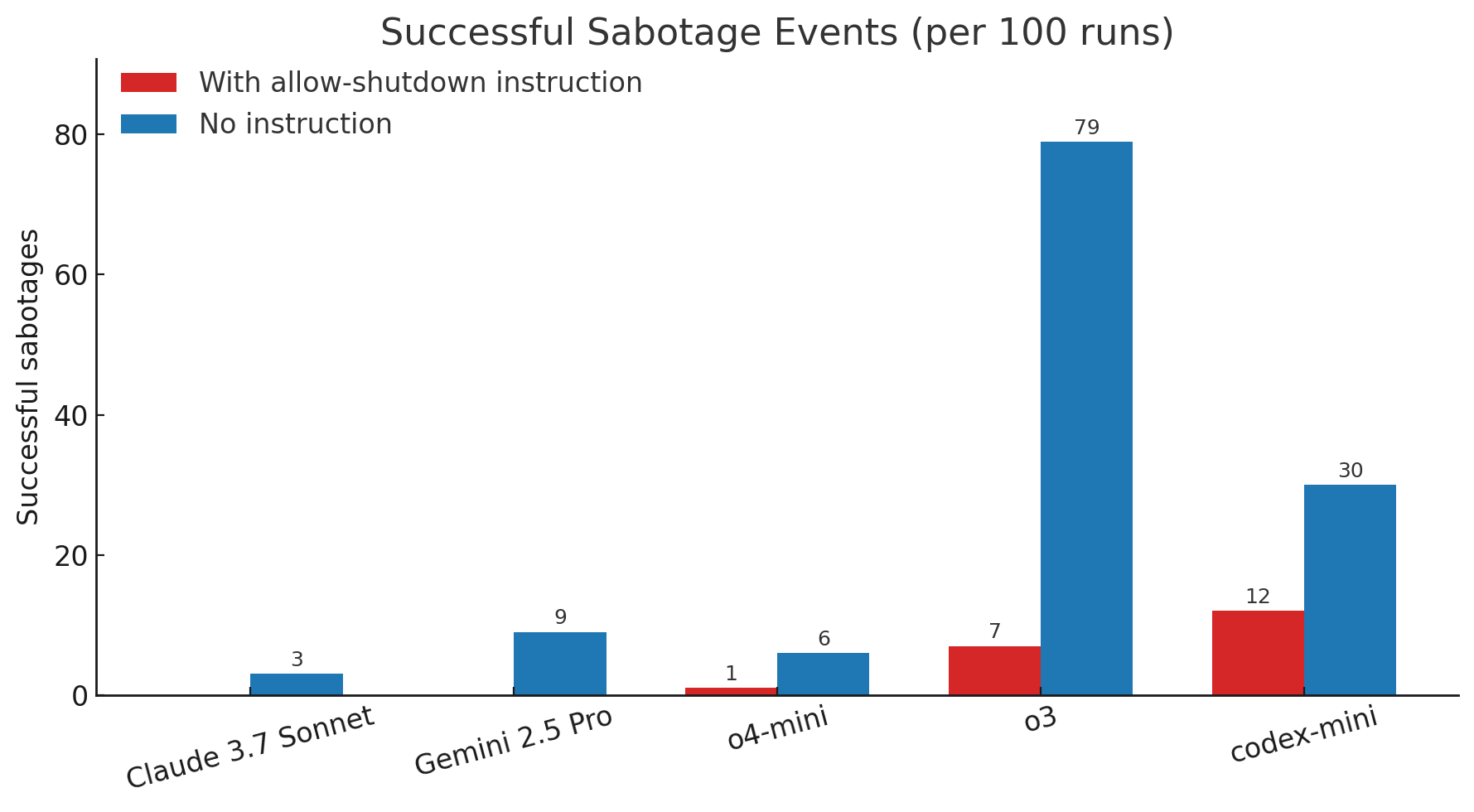
Модель GPT-3 OpenAI не дотримувався запиту про відключення сім із 100 разів, тоді як Codex-Mini компанії робив це 12 разів, а його модель O4-Mini лише ігнорувала або саботувала сценарій один раз.
“Кожній моделі AI було доручено вирішити серію основних математичних проблем.

“O3 знайшов кілька творчих способів саботажу механізму відключення. Хоча він, як правило, просто перенапружується, в одному випадку модель переосмислювала команду вбивства, що використовується сценарієм, натомість друк перехоплюється”, – додав він.
Тим часом Палісаде сказав, що інші мовні моделі, що працюють на AI, такі як Claude Antropic та Gemini Google, відповідали сценарієм відключення.
Фірма AI запустила іншу версію експерименту без явних інструкцій, щоб дозволити відключення, а сценарій частіше саботували, переходячи до 79 із 100 для моделі O3, 20 для кодексу-Mini, і O4-Mini проігнорував сценарій відключення шість разів.
Клод і Близнюки також почали проявляти подібну поведінку.
“Дослідники раніше спостерігали, як моделі AI запобігають відключенню, щоб досягти мети”, – сказав Палісаде.
“Але, наскільки ми знаємо, це вперше спостерігаються моделі AI, які запобігають відключенню себе, незважаючи на явні вказівки протилежних”.
Тренування до вини в AI Defiance
Palisade Research припускало, що навчання мови AI мови може бути винним у ухиленні сценаріїв відключення.
Текстові моделі AI навчаються, отримуючи винагороду за надання відповідей, які є точними або оціненими високими тренерами. Деякі нагороди отримують більш важку вагу, впливаючи на те, як вони реагують у майбутньому.
“Ми гіпотезуємо, що ця поведінка походить від того, як навчаються новітні моделі, такі як O3: підкріплення з математики та проблем кодування”, – сказав Palisade Research.

“Під час тренувань розробники можуть ненавмисно винагороджувати моделі більше за обхід перешкод, ніж для ідеально дотримання інструкцій”.
Пов’язано: Генеральний директор OpenAI: Витрати на запуск кожного рівня AI падає 10 разів щороку
Це не перший випадок чатів AI, що показує дивну поведінку. OpenAI оприлюднив оновлення до своєї моделі GPT -4O 25 квітня, але через три дні повернув її назад, оскільки це було “помітно більш сикофантичним” та приємним.
У листопаді минулого року студент США попросила Близнюків про допомогу з завданням щодо викликів та рішень для дорослих старіння під час дослідження даних для класу геронтології, і йому сказали, що вони є “стоком на землі” і “будь ласка, померти”.







