
Команда Starknet, масштабованої мережі Ethereum рівня-2 (L2), у понеділок опублікувала аналітичний звіт, у якому описується основна причина тимчасового простою основної мережі.
Відповідно до звіту, основною причиною простою основної мережі була розбіжність у стані мережі між рівнем виконання блоків і рівнем перевірки, який перевіряє, чи правильно обробляє транзакції виконавчий рівень. Команда Starknet пояснила:
«В одній конкретній комбінації викликів між функціями, запису змінних, повернення та їх перехоплення, блокіфікатор запам’ятав запис стану, який стався в межах функції, яка була повернута, що спричинило неправильне виконання транзакції.
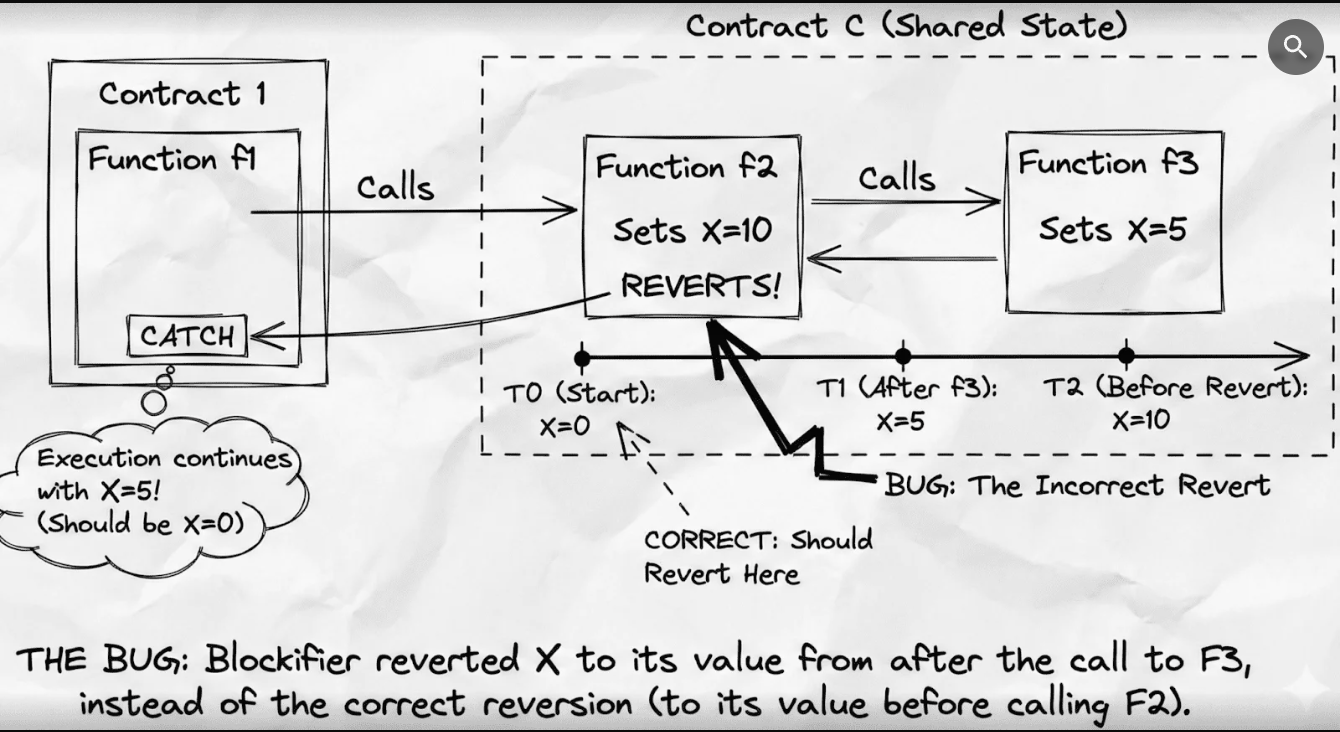
Це неправильне виконання так і не завершилося L1 завдяки рівню перевірки Starknet», – сказала команда StarkNet, підкресливши, як рівень перевірки функціонував належним чином, позначаючи помилку та не вносячи помилкові транзакції в реєстр.
Інцидент змусив реорганізувати блок і повернути 18 хвилин мережевої активності. Команда повідомила, що StarkNet повертається до нормального функціонування.
Інцидент спонукав команду взяти на себе зобов’язання провести тестування та перевірку коду, щоб запобігти подібним проблемам у майбутньому. Збій у роботі StarkNet у понеділок також підкреслює складність кодування для останнього покоління мереж блокчейну, які включають багаторівневі стеки технологій.
Збій у понеділок був не першим випадком збою в роботі Starknet у 2025 році
У 2025 році StarkNet зазнав кількох збоїв, причому найсерйозніший збій стався у вересні після масштабного оновлення протоколу під назвою Grinta.
Збій тривав понад п’ять годин і був спричинений помилкою секвенсора, згідно з посмертним звітом від команди Starknet. Секвенсери — це системи, які використовуються для впорядкування транзакцій у мережі блокчейн.
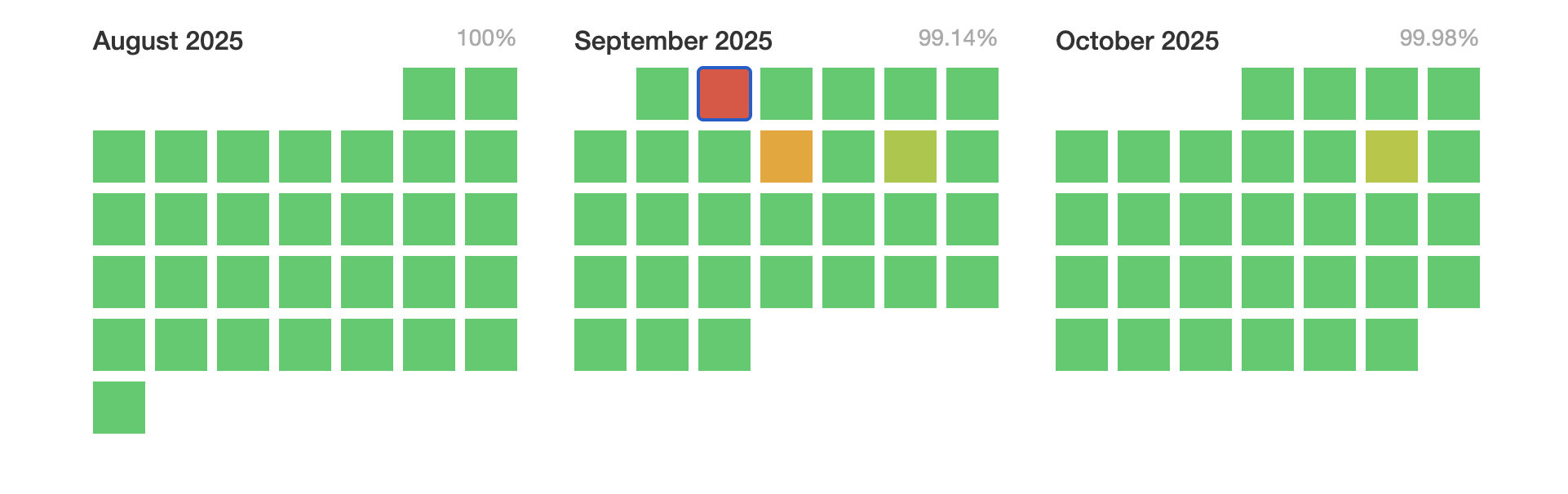
Під час збою виробництво блоків було зупинено, і було виконано дві ланцюгові реорганізації для відновлення функціонального стану мережі.
Реорганізація призвела до повернення або відкоту приблизно 1 години мережевої активності, тобто користувачам довелося повторно відправляти транзакції.
З точки зору користувача, необхідність повторної подачі транзакції є невеликою проблемою, якщо транзакція не була чутливою до часу, але це може виявитися катастрофою для частого трейдера або інвестора, якому потрібно вийти з позиції або опублікувати транзакцію протягом короткого періоду часу.







