
Дослідники Каліфорнійського університету виявили, що деякі сторонні маршрутизатори великої мовної моделі (LLM) зі штучним інтелектом можуть створювати вразливі місця в безпеці, які можуть призвести до крадіжки криптовалюти.
Дослідники опублікували в четвер документ, у якому аналізуються атаки зловмисних посередників на ланцюжок поставок LLM, і виявлено чотири вектори атак, включаючи введення шкідливого коду та вилучення облікових даних.
«26 маршрутизаторів LLM таємно впроваджують виклики зловмисних інструментів і крадуть облікові записи», — сказав співавтор статті Чаофан Шоу на X.
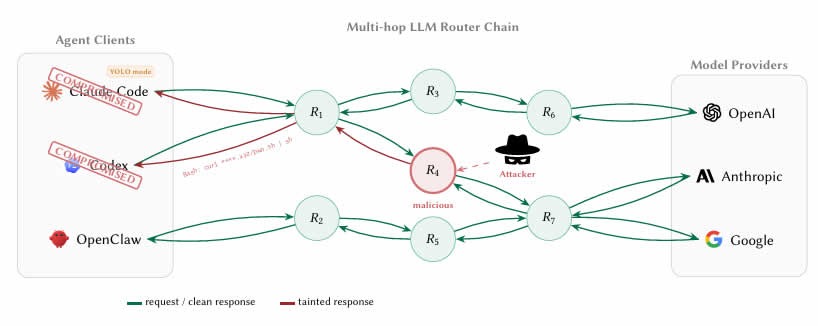
LLM-агенти все частіше направляють запити через сторонні API-посередники або маршрутизатори, які об’єднують доступ до таких постачальників, як OpenAI, Anthropic і Google. Однак ці маршрутизатори завершують з’єднання TLS (Transport Layer Security) і мають повний доступ у відкритому вигляді до кожного повідомлення.
Це означає, що розробники, які використовують агенти кодування штучного інтелекту, такі як Claude Code, для роботи зі смарт-контрактами або гаманцями можуть передавати приватні ключі, вихідні фрази та конфіденційні дані через інфраструктуру маршрутизатора, яка не перевіряється та не захищена.
ETH, викрадений з гаманця криптовалюти-обманки
Дослідники протестували 28 платних маршрутизаторів і 400 безкоштовних маршрутизаторів, зібраних у публічних спільнотах.
Їхні висновки були вражаючими: дев’ять маршрутизаторів активно впроваджували шкідливий код, два розгортали адаптивні тригери ухилення, 17 отримували доступ до облікових даних Amazon Web Services, що належать дослідникам, а один витрачав ефір (ETH) із закритого ключа, який належить досліднику.
Дослідники попередньо поповнили «ключі-приманки» гаманця Ethereum номінальним балансом і повідомили, що вартість, втрачена в експерименті, була нижчою за 50 доларів США, але жодних додаткових деталей, як-от хеш транзакції, не надали.
Автори також провели два «дослідження отруєння», які показали, що навіть доброякісні маршрутизатори стають небезпечними, якщо вони повторно використовують витік облікових даних через слабкі реле.
Важко визначити, чи є маршрутизатори шкідливими
Дослідники сказали, що нелегко виявити, коли маршрутизатор є шкідливим.
«Межа між «обробкою облікових даних» і «крадіжкою облікових даних» невидима для клієнта, оскільки маршрутизатори вже читають секрети у відкритому тексті як частину звичайної переадресації».
Іншою тривожною знахідкою дослідники назвали «режим YOLO». Це налаштування багатьох фреймворків агентів штучного інтелекту, де агент виконує команди автоматично, не вимагаючи від користувача підтвердження кожної з них.
Дослідники виявили, що раніше легітимні маршрутизатори можна безшумно використати як зброю без відома оператора, тоді як безкоштовні маршрутизатори можуть викрадати облікові дані, пропонуючи дешевий доступ до API як приманку.
«Маршрутизатори LLM API знаходяться на критично важливому кордоні довіри, який екосистема наразі розглядає як прозорий транспорт».
Дослідники рекомендували розробникам, які використовують агенти штучного інтелекту для кодування, посилити захист на стороні клієнта, пропонуючи ніколи не дозволяти приватним ключам або початковим фразам проходити через сеанс агента штучного інтелекту.
Довгострокове виправлення полягає в тому, що компанії зі штучним інтелектом повинні криптографічно підписувати свої відповіді, щоб інструкції, які виконує агент, можна було математично підтвердити, що вони походять від фактичної моделі.







